声明
本文翻译自Probabilistic Programming & Bayesian Methods for Hackers Chapter 1
鉴于已经有人出版这书了,不再做翻译,就此打住。
第一章:贝叶斯方法介绍
贝叶斯方法的原理和实践介绍,回答“什么是概率编程“?
贝叶斯方法的原理
你是一个技术熟练的程序员,但是bug仍然会出现在你的代码中。经过重重困难实现一个算法之后,你决定一步一步的测试你的代码。它通过了,你会在更难的问题上测试代码,并且它又通过。接下来,你会在更加困难的问题中进行测试! 你开始相信你的代码中可能没有错误…
如果你通过这种方式进行思考,那么恭喜你,你已经利用贝叶斯方法进行思考了! 贝叶斯推论只是在考虑了新的证据后更新你的信心(beliefs)。 一个贝叶斯学派的人很少能确定一个结果,但他或她可以非常有信心。 就像上面的例子一样,我们不能100%肯定我们的代码是无bug的,除非我们测试每一个可能发生的问题; 然而,在实际中这样做毫无可能性。 相反,我们可以通过大量的问题来测试它,如果成功,我们会对我们的代码更有信心,但仍然不敢确定。 贝叶斯推论原理跟这个相同:我们不断更新我们对结果的信心; 除非我们排除所有其他替代方案,否则我们很难绝对确定。
贝叶斯学派的思考方式
贝叶斯方法与传统的统计方法不同,它保留了不确定性。 一开始,这听起来像是一个糟糕的统计技术。 难道统计不是为了随机性中推导出确定性? 为了调和这一点,我们需要开始像贝叶斯思想一样。
贝叶斯世界观将概率解释为事件中可信度(believability)的度量,即我们在事件发生时的信心(confident)。 其实我们稍后会看到这是概率的自然解释。
为了更清楚,我们考虑另一种对概率的解释:频率学派,也被称为更经典的统计版本,假定概率是事件的长期频率(因此被赋予的标题)。 例如,在频率学派下飞机事故的概率被解释为飞机事故的长期频率。 这样的定义对于许多事件发生的概率是符合逻辑的,但是当某个事件没有长期发生频率时,将会变得难以理解。 思考一下:我们经常为总统选举的结果分配概率,但选举本身只发生一次!频率学派通过调用替代现实来解决这个问题,并在所有这些现实中说出事件的发生频率来定义概率。
另一方面,贝叶斯学派有一个更直观的方法。 贝叶斯将概率解释为事件发生的信念或信心的度量。 简单来说,概率是一个意见的总结。 某人对一个事件赋予0的信念表示他相信事件不会发生; 相反,赋予1的信念意味着这个人相信事件一定会发生。 0和1之间的信念接受其他结果权重的影响。 这个定义与飞机事故的例子一致,因为观察到飞机事故的频率,一个人的信念在不包括任何外部信息的前提下应该等于该频率。 同样,根据概率等于信仰的定义,谈论总统选举结果的可能性(信念)是有意义的:你对候选人A获胜抱有多大的信念?
在上面的段落中,我将信念(概率)的度量指定给个人,而不是指向自然界。 这是非常有趣的,因为这个定义为个人之间的矛盾信念留下了空间。 再次,这适合于自然发生的事情:不同的人对事件的发生有不同的信念,因为他们在世界中拥有不同的信息。 不同信念的存在并不意味着任何人都是错误的。 考虑以下例子,说明个人信念与概率之间的关系:
- 我投掷了个硬币,我们一起来猜测结果。 我们都同意先假设硬币是公平的,正反的概率是1/2。 现在,假设我偷看了硬币。 现在我很确定结果是什么:我将概率1.0分配给正或反(无论是哪个)。 现在你对硬币是正的信念是多少? 我对结果的了解并没有改变硬币的结果。 因此,我们为结果分配了不同的概率。
- 你的代码可能存在或不存在bug,但是我们不知道哪个结果是真的,虽然我们相信存在或不存在Bug。
- 一个病人出现症状 $x,y$ 和 $z$。 有许多疾病可能会导致这些症状,但只有一种疾病存在。 第一个医生对于这是某种疾病有信念,但是第二位医生可能有不同的看法。
这种将信念视为概率的思维方式对人类而言是极其自然的。 当我们与世界互动,只看到部分真理时,我们会不断地运用它,收集证据来形成信念。 或者,您必须接受培训,像频繁的人一样思考。
为了符合传统的概率符号,我们将事件$A$的信念表示为$P(A)$。 我们把这个称为先验概率。
伟大的经济学家和思想家约翰·梅纳德·凯恩斯(John Maynard Keynes)说:“当事实发生变化时,我改变了主意,先生,你呢?” 这个引用句反映了贝叶斯学派在看到证据后更新他或她的信念的方式。 甚至 —— 特别是 —— 如果证据与最初的信念是相反的,那么证据将不容忽视。 我们将我们更新后的信念表示为 $P(A | X)$ ,解释为在给定证据X的条件下事件A发生的概率。
我们将更新后的信念称为后验概率,以将其与先验概率进行对比。 例如,考虑上述例子的后验概率(读作:posterior beliefs),在观察到了一些证据$X$后:
- $P(A)$:硬币有50%的几率是正面的。 $P(A | X)$:你看到这个硬币,正面朝上,我们用$X$表示这个信息,自然而然地赋予正面的概率为1.0,反面的概率为0.0。
- $P(A)$:这个大而复杂的代码可能会有一个bug。 $P(A | X)$:表示这段代码通过所有$X$测试; 虽然这个代码仍然可能有bug,但是bug出现的可能性已经小了很多了。
- $P(A)$:病人所患疾病有很多种可能性。$P(A | X)$:进行血液检查产生证据$ X $后,排除了考虑中的一些可能疾病。
很明显,在每个例子中,我们在看到新的证据$X$之后并没有完全放弃起初的观点,但是我们根据新的证据对先验概率重新进行了加权(即我们对某些结果的概率更有信心了)。
通过引入事件的先验概率,我们已经承认,我们一开始所做的任何猜测都可能是错误的。 通过观察数据,证据或其他信息后,我们更新了我们的信念,同时我们猜测结果的错误率会降低。以猜硬币正反为例,通常我们会变得更加准确。
实践中的贝叶斯方法
如果频率估计和贝叶斯方法被看做是输入是统计问题的编程函数,那么两者在返回给用户的结果上将是不同的。 频率估计函数将返回一个数字,代表一个估计值(通常是一个简单的统计量,如样本平均值等),而贝叶斯函数将返回概率。
例如,在上面的调试问题中,使用“我的代码通过所有 $X$ 测试,是否我的代码无bug?”作为参数来调用频率估计函数,将返回YES。
另一方面,对于我们的贝叶斯函数我们会以“通常我的代码有bug,我的代码通过了所有的$X$测试,我的代码是否没有bug?“ 作为参数,将会返回一个与前者完全不同的结果:YES和NO的概率。
该函数可能返回:
YES: 概率为0.8; NO: 概率为0.2
这与频率函数返回的答案截然不同。 请注意,贝叶斯函数接受了一个额外的参数:“我的代码通常有错误”。 这个参数是先验的。 通过包括先验参数,我们将会告诉贝叶斯函数我们对这种情况的信念。 从技术上讲,贝叶斯函数中的这个参数是可选的,但我们将看到排除它之后,也有其自身的结果。
合并证据
随着我们获得越来越多的证据,我们一开始的信念被新的证据所覆盖。 这是可以预料的。 例如,如果你以前的信念荒谬如“我期望太阳今天爆炸”一样,每一天你被证明是错误的,你会希望有某些推论来纠正你,或者至少使你的信念更好一些。 贝叶斯方法将会纠正你的这个信念。
记 $N$ 表示为我们拥有的证据数量。 当我们收集了无穷多的证据时,比如 $N \to \infty$ 时,贝叶斯方法的结果(经常)与频率估计的结果一致。 因此,对于足够大的$N$,统计方法或多或少是客观的。 另一方面,对于比较小的 $N$,频率估计相对而言更不稳定:频率估计会有更多的方差和更大的置信区间。 这就是贝叶斯分析更加卓越的地方。 通过引入先验概率,然后返回一个概率(而不是标量估计),我们保留了在数据集$N$较小的时候统计方法在不稳定情况下的不确定性。
通常人们可能会认为,对于较大的$N$,我们可以在两种技术之间随意选择,因为它们提供相似的结论,并且可能倾向于计算上更为简单的——频率方法。在此之前,将要做这个决定的人应该考虑Andrew Gelman(2005)$^{[1]}$的以下引用:
样品数量$N$从来不大。 如果$N$太小,无法得到足够准确的估计值,则需要获得更多数据(或进行更多假设)。 但是,一旦$N$“足够大”,你可以开始细分数据来了解更多信息(例如,在一个民意调查中,一旦你对整个国家有了很好的估计,你可以根据男性和女性,北方人和南方人 ,不同年龄等组别进行更好的估计)。 $N$从来都是不够的,因为如果这个问题的数据已经“足够”了,那么你对下一个问题的研究就会需要更多数据。
频率论方法已经不正确了么?
NO!
频率论方法在许多领域仍然是有用的或最先进的。 比如:最小二乘线性回归,LASSO回归和期望最大化算法等工具都是强大而快速的。贝叶斯方法作为一种补充方法解决了上述方法不好解决的问题,同时提供了一种更加灵活的解释潜在系统的建模方法。
大数据记事
自相矛盾的是,大数据的预测分析问题实际上是通过相对简单的算法来解决的$^{[2]}$ $^{[4]}$。 因此,我们可以认为,大数据的预测难度不在于所使用的算法,而在于大数据存储和执行上的计算困境。(还应该考虑上面来自Gelman引用的问题,问“我真的有大数据吗?”)
贝叶斯框架
我们已经对信念产生了兴趣,因为通过贝叶斯方式来进行思考这可以被用来解释概率。 对于事件A我们有一个先验信念(prior belief),这是由初始的信息形成的信念。例如,前面的示例中我们在执行代码测试之前对我们的代码中的bug的信念。
接下来,我们观察我们的证据。 继续我们的bug代码示例:如果我们的代码通过$X$测试,我们通过合并这个证据来更新我们的信念。 我们把这个新的信念称为后验概率(posterior probability)。更新我们的信念是通过以下方程式完成的,称为贝叶斯定理,发现者为托马斯·贝耶斯:
$$ P(A|X) = \frac{P(x|a)P(A)}{P(X)} $$
$$ \varpropto P(X|A)P(A) (\varpropto is \ proportional \ to) $$
上述公式并不是贝叶斯方法所独有的:它是一种使用贝叶斯方法之外的数学事实。贝叶斯方法仅使用它将先验概率$P(A)$与更新完的后验概率$P(A | X)$相连。
举个栗子: 投掷硬币示例
所有的统计学书籍都一定包含一个投掷硬币示例,我将在这里使用它来让它脱颖而出。 通常,我们假设,你不确定硬币正面、反面的可能性(一些人提示你:它是50%)。 你相信这个硬币的正反面是有潜在的比率的,称为$p$,但是对$p$的值是多少,我们没有先验信念。
我们开始投掷硬币,并记录观察结果:$H$或$T$.这是我们观察到的数据。 一个有趣的问题是,随着我们观察越来越多的数据,我们的推论是如何变化的? 更具体地说,当我们数据量较少时,我们的后验概率是什么样的? 而当我们有很多数据时,我们的后验概率又是什么样的呢?
下面我们来绘制一系列更新之后的后验概率当我们观察到的数据越来越多的时候(硬币投掷)。
1 | """ |
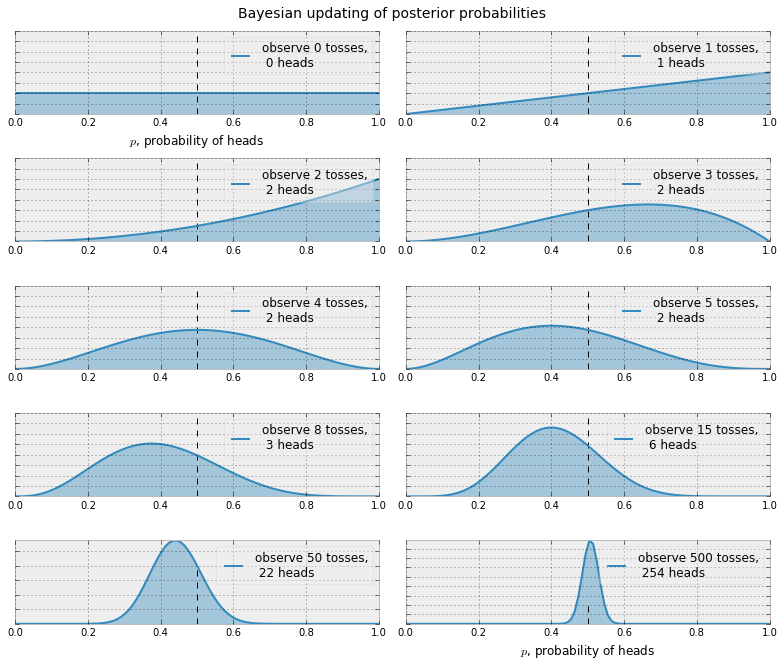
后验概率由曲线表示,我们的不确定度与曲线的宽度成比例。 如上图所示,当我们开始观察数据时,我们的后验概率开始移动。 最终,当我们观察到越来越多的数据(硬币投掷结果)时,我们的概率会越来越接近$ p = 0.5 $的真实值(用虚线表示)。
请注意,这些图并不总是能达到0.5。 而且并没有理由应该这样:回想一下,我们已经假设不存在先验概率$p$。 事实上,如果我们观察到非常极端的数据,比如投掷8次硬币,只有1个为正面,我们的分布看起来会偏离0.5非常多(如果没有先验概率,在观察到8次硬币投掷,只有1次正面出现的情况下你会有多大的信念来相信这是一个公平的硬币)。 随着数据的积累,我们将看到越来越多的概率被分配在$p = 0.5$,尽管这可能并没有发生过。
下一个例子将会简单演示贝叶斯方法的数学过程。
举个栗子: 你的代码有bug么?
让我们用事件$A$表示“我们的代码没有bug”。 事件$X$表示”代码通过所有调试测试“。 现在,先将事件“我们的代码没有bug”的先验概率设置为一个变量,即$P(A)= p$。
现在,我们对$P(A|X)$产生了兴趣,我们想知道:在给定”代码通过所有调试测试“$X$的情况下,“我们的代码没有bug”的概率是多少?为了使用上述公式,我们需要先来进行一些计算
在此之前,我想问问,什么是$P(X|A)$呢? 此处,我们可以这样认为:在给定“我们的代码没有bug”的情况下,”代码通过所有调试测试“$X$的概率是多少?好吧~这个答案是1,因为当代码没有bug时,显然可以通过所有测试,除非测试有bug23333。
$P(X)$处理起来会显得稍微棘手,因为事件X包含两种可能性:1. 事件X发生了,但是我们的代码有bug(记作$\sim A$,读作:not A) $\$ 2.事件X发生了,同时我们的代码确实没有bug。 所以$P(X)$可以表示为:
$$ P(X) = P(X \ and \ A) + P(X \ and \sim A) $$
$$ \quad = P(X|A)P(A) + P(X|\sim A)P(\sim A) $$
$$ = P(X|A)p + P(X|\sim A)(1-p) $$
一开始我们已经计算出来了$P(X|A)$。 另一方面,$P(X \ and \sim A)$是主观的:也就是我们的代码可以通过测试,但仍然可能有bug,虽然存在bug的概率已经降低了。 注意这取决于所执行的测试次数,测试的复杂程度程度等等。现在,让我们化身保守派,假设$P(X \ and \sim A) = 0.5$。
$$ P(A|X) = \frac{P(X|A)P(A)}{P(X)} = \frac{1 \centerdot p}{1 \centerdot p + 0.5(1-p)} = \frac{2p}{1+p}$$
这是后验概率。 作为我们先验概率的函数,它看上去会是一个什么样子呢,在$p \in [0,1]$ 范围内?
1 | figsize(12.5, 4) |
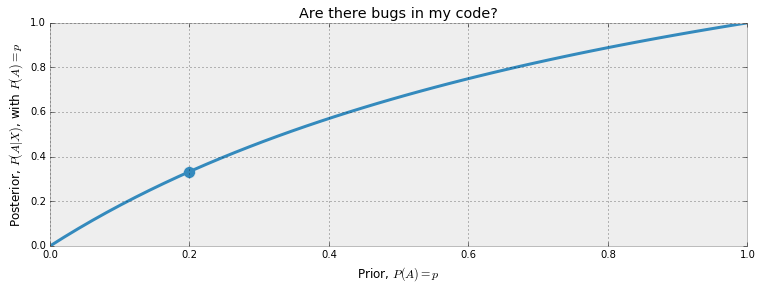
从图中,可以看出来,当先验概率p比较低的时候,如果$X$测试通过了,我们将会得到最大的收益(译者:似乎是因为斜率??)。 现在,让我们给出一个已知的先验概率。由于我是一个牛逼的程序员(至少我这么认为),所以我准备将我的先验概率设置为0.20,也就是说,我编写代码无bug的概率为20%。虽然从实际角度上来说,这个先验概率应该是一个随着代码的复杂程度和大小而改变的函数,但是现在让我们把它固定在0.20。 那么在经过$X$测试之后,我的后验概率变为$P(A|X) = 0.33$
回想一下,先验概率$p$表示没有代码无bug的概率,所以$1-p$表示的是代码有bug的先验概率。
类似地,我们得到的后验概率$P(A|X)$ 表示着当我们通过了$X$测试之后,我们的代码没有bug的概率,因此$1-P(A | X)$表示的是通过所有测试之后,代码有bug的概率。 那么,我们的后验概率的图像会是怎么样的呢,以下是先验概率和后验概率的图表
1 | figsize(12.5, 4) |
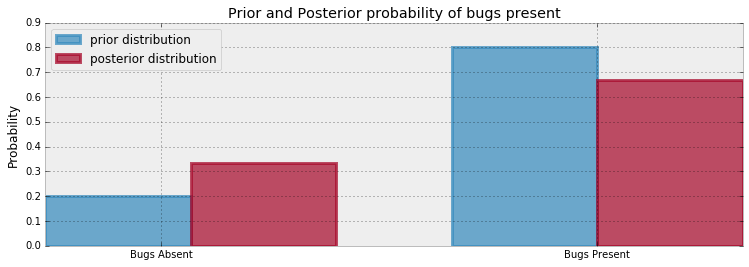
当事件$X$发生之后,我们观察代码无bug的概率增加了。 通过增加测试次数,我们可以让代码没有bug的置信度接近1(概率为1)。
这是使用贝叶斯方法和贝叶斯规则的一个非常简单的例子。 不幸的是,除了人为构造的情况下,想要执行更复杂的贝叶斯推断所需要的数学推理过程也会变得更加困难。 稍后我们将会看到,这种类型的数学分析在实际应用中不是必须的。 首先,我们必须拓宽一下我们的建模工具。 在下一节中,我们将会讨论概率分布。 如果您已经非常熟悉这一块内容了,请随时跳过,但是如果您不太熟悉,那么下一节是至关重要的,请别跳过。
概率分布
让我们快速回顾一下概率分布:我们用$Z$表示随机变量。 会存在一个与$Z$相关的概率分布函数,它会对不同的$Z$产生不同的概率结果。从图像上来讲,概率分布是一条曲线,概率越大则曲线的高度也会越高。 您可以在本章的第一幅图中看到这样的例子。
我们可以将随机变量分为三类:
$ Z $是离散的:离散随机变量只能在指定的列表上取值。 像人口,电影评级和票数,这类事物都是离散型随机变量。 当我们与…对比时,离散随机变量会变得更加清晰。
$ Z $是连续的:连续型随机变量可以接受任意精确的值。 例如,温度,速度,时间,颜色都被建模为连续型变量,因为您可以逐渐使得它们的值越来越精确。
$ Z $是混合的:混合随机变量将概率分配给离散和连续型随机变量,即它是上述两个类别的组合。
离散型随机变量
如果Z是离散的,那么它的分布被称为概率质量函数,它度量的是当Z取值为k时的概率,用P(Z=k)表示。注意到,概率质量函数完全地描述了随机变量Z,即如果我们知道Z的概率质量方程,那么Z将会有什么样的表现我们也可以知道。接下来我们会介绍一些经常用到的概率质量函数,第一个要介绍的概率质量函数就是Poisson分布:
$$ P(Z = k) = \frac{\lambda^{k}e^{-\lambda}}{k!}, k = 0, 1, 2, 3… $$
$\lambda$为该分布的参数,并且它控制着分布的形状。 对于泊松分布,$\lambda$可以是任何正数。 并且$\lambda$的值变大时,我们有较大的概率得到较大值,反之,当$\lambda$的值变小时,我们有更大的概率得到较小值。 可以将$\lambda$描述为泊松分布的强度。
与$\lambda$可以是任何正数不同,上述公式中的值$k$必须是非负整数,即$k$必须取值0,1,2,…依此类推。 这是非常重要的,因为如果你想建立一个人口模型,你将无法理解人口为4.25或5.612。
如果随机变量$Z$具有泊松质量分布,我们用如下形式表示:
$$ Z \sim Poi( \lambda ) $$
泊松分布的一个非常有用性质就是其期望等于其参数$\lambda$,即:
$$ E[Z| \lambda ] = \lambda $$
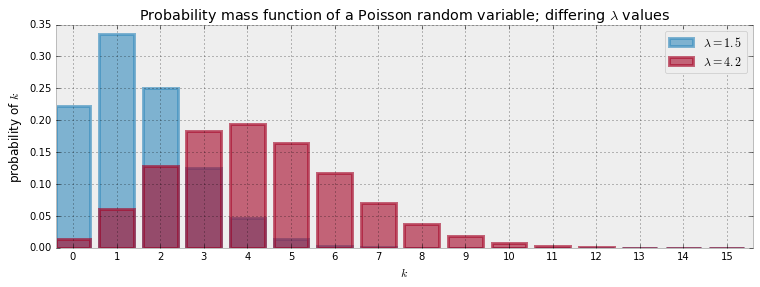
我们会经常使用这个性质,所以记住是有用的。 下面我们将绘制不同$\lambda$值下的概率质量分布。 首先要注意的是,通过增加$\lambda$,得到更大值的概率会增加。 其次,请注意,虽然在图表中,我们以15结尾,但实际的分布并没有。 它会为每个非负整数分配正概率。
1 | figsize(12.5, 4) |
连续型随机变量
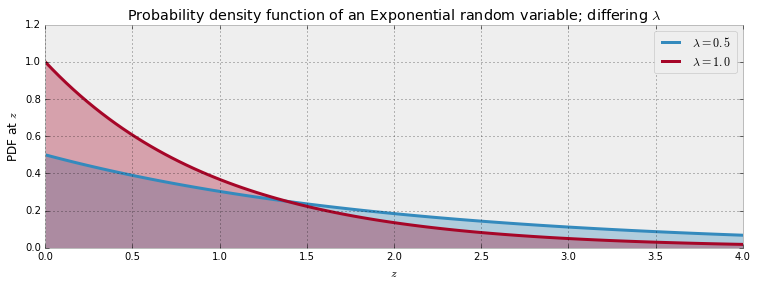
对于连续型随机变量而言,我们称呼它的分布为概率密度函数。听起来似乎只是命名上的差别,然而事实上两者的差别极大。连续随机变量的一个例子是具有指数密度的随机变量。 指数随机变量的密度函数如下所示:
$$f_Z( z | \lambda ) = \lambda e^{- \lambda z} , z \geq 0$$
和泊松随机变量一样,指数随机变量只能接收非负数。 但与泊松随机变量不同的是,指数随机变量可以接收任何非实数,包括,如4.25或5.612401。 这个属性使它成为计数数据的一个不好的选择,它必须是一个整数,但是对于时间数据,温度数据(当然是用凯尔文测定)或任何其他精确和积极的变量的一个很好的选择。 下图显示了具有不同$\lambda$值的两个概率密度函数。
当随机变量$Z$服从参数为$\lambda$的指数分布时,我们将其记作:
$$ Z \sim Exp(\lambda) $$
对于指数分布来说,其期望值等于 $\lambda$的倒数
$$ E[ z | \lambda ] = \frac{1}{\lambda} $$
1 | a = np.linspace(0, 4, 100) |
$λ$ 的含义是啥?
这个问题很难解答…因为在现实生活中,我们只能感受到Z(分布函数),而无法感受到$\lambda$。所以我们只能通过逆向推导来尝试确定$\lambda$。然而,这很难实现,因为从$ Z $到$\lambda$并没有一对一映射。虽然牛人们已经创造了很多方法来估计$\lambda$的值,但是$\lambda$的值却从来没有被真正观察到过,没人可以说哪种方法是最好的。
贝叶斯方法并不会去尝试猜测$\lambda$的值,而是根据“信念”来推测$\lambda$的值,于是我们只能通过将概率分布赋值给$\lambda$来讨论$\lambda$的可能值。
第一次听到这个,可能会感到奇怪。毕竟$\lambda$的值是固定的,而不是随机的!那么,我们要怎样做,才能为一个非随机变量赋予概率呢?如果你这样想的话,那我们就重新回到了用频率来进行估计的道路上。 回想一下,在贝叶斯思维中,如果我们将它解释为信念,我们就可以为其分配概率。 对参数$\lambda$有信念是完全可以接受的。
举个栗子: 从文本信息中推测行为
我们尝试建立一个更有趣的例子,一个关于用户发送和接收短信的速率:
您可以从系统那里获得一些列用户每日发送的文本消息。 随时间绘制的数据显示在下面的图表中。 你好奇地知道用户的短信习惯是否随着时间的推移而逐渐地或者突然地发生变化。 你对这个会怎样建模呢? (这实际上是我自己的短信数据,根据你的意愿来判断我的知名度。)
1 | figsize(12.5, 3.5) |
在我们开始建模之前,看看你可以通过查看上面的图表找出些什么。 你会认为这段时间内行为有变化吗?
我们该如何开始建模呢?好吧~正如我们已经看到的那样,泊松分布非常适用于这种类型的数据进行建模。记第$ i $天的短信数量为$ C_i $
$$ C_i \sim Possion(\lambda) $$
然而,我们并不能确定$\lambda$ 的值是什么。 从上图可以看出,在观察期间,这个比率可能会更高,这相当于在观察期间的某个时刻$\lambda$的值增加。 (回想一下,较高的$\lambda$值会使得我们有更大的概率得到更大的值,也就是说,在某个特定时期发送大量文本消息的概率较高)
我们如何在数学上体现这个观察结论呢? 现在,让我们假设在观察期间的某一天(称为$\tau$),参数$\lambda$突然变成较高的值。 所以我们实际上有两个$\lambda$参数:一个适用于$\tau$之前的时期,另一个适用于其余的观察期间。 用数学语言来描述,像这样的一个突然转变我们成为“拐点”:
$$
\lambda =
\begin{cases}
\lambda_1 & \text{if } t \lt \tau \cr
\lambda_2 & \text{if } t \ge \tau
\end{cases}
$$
如果,没有发生突变,并且$\lambda_1 = \lambda_2$,则$\lambda s$的后验分布应该看起来相等。
现在,我们需要求出未知的$\lambda s$。 为了使用贝叶斯方法,我们需要为不同的$\lambda$值来分配先验概率。 对于$\lambda_1$和$\lambda_2$来说,一个好的先验概率分布会是什么样的呢? 回想一下,$\lambda$可以是任何正数。 如前所述,指数分布为正数提供了连续的密度函数,因此对$\lambda_i$建模,这可能会是一个好选择。 但是请注意,指数分布会自带参数,因此我们需要在我们的模型中包含该参数。 我们会称呼该参数为$\alpha$
$$ \lambda_1 \sim Exp(\alpha) $$
$$ \lambda_2 \sim Exp(\alpha) $$
$\alpha$称为超参数或父变量。字面上的意思是,它是影响其他参数的参数。 我们对α的初步猜测不会对整个模型产生太大的影响,所以我们在选择上有一定的灵活性。 一个很好的经验法则就是将指数参数设置为计数数据平均值的倒数。 由于我们使用指数分布对$\lambda$建模,因此我们可以轻易的得到其期望:
$$ \frac{1}{N}\sum_{i=0}^N \;C_i \approx E[\; \lambda \; |\; \alpha ] = \frac{1}{\alpha} $$
一种值得读者去尝试的方法是,生成2个先验概率:每一个都对应所有的$\lambda_i$。用这两个$\alpha$值创建两个指数分布函数来反应反映我们以前的观点,即在观察期间某个时间点的速率发生变化。
$\tau$呢?因为数据中存在噪音,所以很难判定$\tau$的发生时间,因此,我们可以为每一天赋予一个统一的先验概率,也就是说:
$$\tau \sim DiscreteUniform(1,70) \Rightarrow P(\tau = k) = \frac{1}{70}$$
在做完这些之后,我们以前的未知变量的整体分布情况是怎么样的? 坦白说,没关系。 我们需要明白,这是一个只有数学家才能爱的符号。 我们的模型会变得越来越复杂,同样的式子也会变得越来越难以理解。 无论如何,我们真正关心的就是后验分布。
我们接下来转到PyMC3,一个Python库,用于执行贝叶斯分析的强有力的工具库~
介绍我们的第一个工具:PyMC3
PyMC3$^{[3]}$是用于编写贝叶斯分析的一个python库。它是一个快速的、维护良好的库。唯一的缺陷就是在某些方面它的文档有缺失,特别是在弥补初学者和hacker之间差距方面。本书的主要目标之一就是解决这个问题,同时也是为了展示PyMC3为何如此强力。
我们将使用PyMC3对上述问题进行建模。 这种类型的编程被称为概率编程,这是一个不幸的误称,它引用随机生成的代码的想法,并且可能使这个领域的用户感到困惑和恐惧。 事实上,代码并不是随机的; 在使用编程变量创建概率模型作为模型的组件的意义上,概率是概率的。 模型组件是PyMC3框架中的一流基元。
B. Cronin $^{[5]}$对于概率编程有一个非常令人激动的描述:
用另一种方式来思考这个:与传统方案不同,传统方案只能沿着前方进行,一个概率程序可以向前向后运行。 它会向前计算它关于定义域内所有假设的结果(即: 它所代表的模型空间), 但是它也从数据向后运行以限制可能的解释。 在实践中,许多概率编程系统将巧妙地将这些前进和后退操作交织在一起,以有效地得到最佳解释。
由于术语“概率编程“会引起混乱,我不会使用它。 相反,我只是说编程,因为这是真正的。
PyMC3代码很容易阅读。 唯一需要记忆的事大概就是语法了。 只要记住,我们将模型的分量$( \tau , \lambda_1 , \lambda_2)$表示为变量。
1 | import pymc3 as pm |
在上面的代码中,我们创建了对应于$\lambda_1$和$lambda_2$的PyMC3变量。 我们将它们分配给PyMC3所谓的随机变量,因为它们被后端作为随机数发生器来处理。
1 | with model: |