IRGAN 论文阅读笔记
介绍
本文中,作者将IR领域的研究分为两类:
第一类是经典思维流派,它的主要思想是描述用户的 query 和 document 之间的关联分布,并通过建立统计学习模型得到综合打分,给出合适的检索结果。用符号表示就是 $p \to d$.
第二类是现代思维流派,它的主要思想是将IR看作一个分类(判别)问题,通过同时考虑 query 和 document 的feature,然后预测它们的评分(关联度),最后进行排序,相当于一个Top-N问题。用符号表示就是 $q + d \to r$.
模型
由于本人是做推荐的,接下来的解释,都会从推荐系统的角度进行解读。
整个模型的目标函数
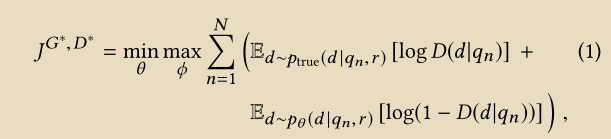
判别模型
它的作用就是尽可能的区别已观测样本和未观测样本。所以优化的目标就是最大化已观测样本和生成样本之间的差距。当然这些未观测样本中可能有正样本,可能有负样本。
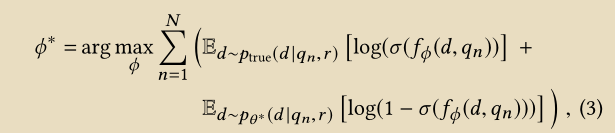
对于判别模型来说,我们在训练它的时候,会将正例、负例,一起喂给模型,多次学习之后。理论上,模型会对于我们选择的正例、负例有一个很好的区分度。
举个例子,训练的数据格式,如下所示:
1 | users = [1, 1, 1, 1] # 表示用户1 |
最后,判别模型的 pytorch 表示为:
1 | # Discriminator |
生成模型
跟普通的GAN不同,在IRGAN中,我们会建立一个候选池,然后,生成模型所生成的 items 就是从候选池中挑选得到的。
生成模型的作用是对于给定的 user ,我们尝试从候选池中,选择最接近已观测样本分布的未观测样本。这里我们用 $P_\theta (d | u, i)$ 表示生成模型,一句话总结它的作用就是尽可能的使得 $P_\theta (d | u, i) \approx p_{true} (d | u, i)$。
从推荐系统的角度来解释,我们会先假设 user 消费过的 itme 存在某种分布$P(\theta)$,然后生成模型会帮我们选择那些 user 未消费过的,但是可能服从$P(\theta)$的item。

训练生成模型的时候,由于 generator 的 target function 为 $J^G (q_n)$,我们对其求导,结果如下图所示。

在上述 policy gradient 公式中, $p_{\theta} (d_k | q_n, r)$ 表示的是生成模型, $f_{\phi} (d_k, q_n)$ 表示的是判别模型。
其中 $log(1 + exp(f_{\phi} (d_k, q_n)))$ 被看作 reward, 用来 update 生成模型。
[todolist: 写一篇关于 Policy gradient 的 blog]
另外,在生成模型中,还有一个 trick 是论文中没有提到的,那就是 重要性采样, 我们会通过重要性采样,来获取generator模型产生的item。
1 | # Generator |
[同样的,在论文提供的Movielens数据集上跑出来的结果如下所示]
个人的一些看法
将GAN的思想引入了 IR 领域,为这一领域引入了新的思想,确实是一个开山之作,但是个人感觉不足的地方在于,整个论文的没有解决一个核心问题 —— 引入GAN之后,可以解决推荐领域的什么问题。
不过新的思想的引入,也确实很牛逼,而且可以预见, GAN + RS 怕是马上就要开始了。