理解Google File System
Google的服务具有的特性是需要用到大数据,而且要面向全球用户提供实时服务,具有这样两个要求的服务,使得google需要大量的分布式机器,而且这些机器还必须能够实时被查询到。
于是,google在以往分布式文件系统的基础上,进行了创新。得到了 GFS(Google File System),它可以运行于廉价的普通硬件上,并提供容错功能。它还可以给大量的用户提供总体性能较高的服务。
1.1 系统架构
以往的分布式系统,是没有中心节点的,但是在 GFS 中,我们将 Metadata(元数据,可以理解为控制信息)保存在 Master节点中,将用户需要的数据保存在 Chuck Sever 中, 这样我们可以方便的从 Master 中得知各个 Chuck Sever 的运行情况,同时 Master 不会成为制约这个系统的瓶颈,而且我们可以使用廉价的普通硬件作为 Chuck Sever 一举多得。
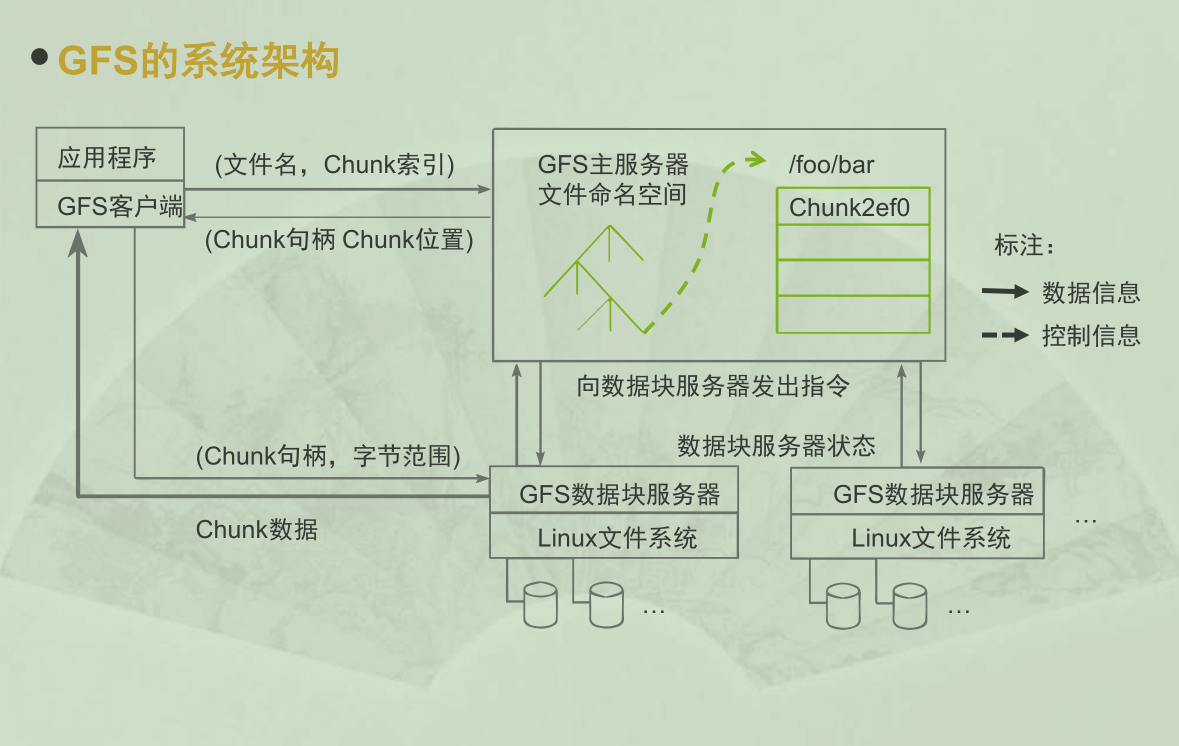
如果所示:
GFS将整个系统节点分为三类角色
- client(客户端) GFS提供给应用程序的访问接口
- Master(主服务器) GFS的管理节点,也就是主节点,负责管理整个文件系统
- Chuck Sever(数据块服务器) 负责具体的数据存储工作
1.1.1 GFS的实现机制
- client 首先访问 Master节点,从 Master 那里知道,自己应该去那些 Chuck Sever 那里去读取、写入数据,然后 client 再访问这个 Chuck Sever 去完成数据读写的工作。这样的设计方法实现了控制流和数据流的分离
- clinet 和 Master 之间只有控制流,没有数据流,这样就极大的减轻了 Master 的负担。
- client 和 Chuck Sever 之间直接传输数据流,同时由于文件被分成多个 Chuck 进行分布式存储, client 可以同时访问多个 Chuck Sever 从而使得整个系统的 I/O 高度并行,系统整体性能得到提升。
1.1.2 GFS的特点
- 采用中心服务器模型
- 可以方便地增加 Chuck Sever
- Master 可以掌握系统内所有 Chuck Sever 的情况,方便进行负载均衡。
- 不存在元数据的一致性问题 (解释一下,元数据就是存储在 Master 中的信息,一个系统内部会有多个 Master,这些 Master 可以看作彼此的备份。)
- 不缓存数据
- 文件操作大部分是流式读写,不存在大量重复读写,使用 Cache 对性能提高不大。
- Chuck Sever 上数据存取使用本地文件系统,不用Cache 就不需要考虑缓存一致性的问题。
- 但是 Master 中的 metadata(元数据) 会缓存。
- 在用户态下实现
- 利用 POSIX 编程接口,提高了通用性。
- Master 和 Chuck Sever 都以进程的方式运行,单个进行不影响整个操作系统。
- GFS和操作系统运行在不同的空间,两者耦合性降低。
1.2 容错机制
1.2.1 Master 容错
Master维护文件系统所有的元数据(metadata),包括名字空间、访问控制信息、从文件到块的映射以及块的当前位置。
另外,每个 Chuck Sever 上都会保存 Chuck 副本的信息,每个 Chuck 默认有三个副本,这样当某个 Chuck 坏了之后,不会影响 Chuck 数据的读取。
当 Master 发生故障时,在磁盘数据保存完好的情况下,可以快速的恢复所有的 metadata。并且为了防止 Master 彻底死机的情况, GFS 还提供了 Master 的远程备份。
1.2.2 Chuck Sever 容错
- GFS采用副本的方式实现Chunk Server的容错
- 每一个Chunk有多个存储副本(默认为三个)
- 对于每一个Chunk,必须将所有的副本全部写入成功,才视为成功写入
- 相关的副本出现丢失或不可恢复等情况,Master自动将该副本复制到其他 Chunk Server
- GFS中的每一个文件被划分成多个Chunk,Chunk的默认大小是64MB
- 每一个Chunk以Block为单位进行划分,大小为64KB,每一个Block对应一个 32bit 的校验和
1.3 系统管理技术
大规模集群安装技术
GFS集群中通常有非常多的节点,需要相应的技术支撑
故障检测技术
GFS构建在不可靠廉价计算机之上的文件系统,由于节点数目众多,故障发生十分频繁
节点动态加入技术
新的 Chunk Server加入时 ,只需裸机加入,大大减少GFS维护工作量
节能技术
Google采用了多种机制降低服务器能耗,如采用蓄电池代替昂贵的UPS