阅读《解析卷积神经网络—深度学习实践手册》期间,所记录下来的笔记,如需转载,请注明出处。
一、绪论
1.1 什么是深度学习?
深度学习以数据的原始形态(raw data)作为算法输入,经过算法层层抽象将原始数据逐层抽象为自身任务所需的最终特征表示,最后以特征到任务目标的映射(mapping)作为结束,从原始数据到最终任务目标,“一气呵成” 并无夹杂任何人为操作。
它和传统方法的差异性可以从下图中看出:
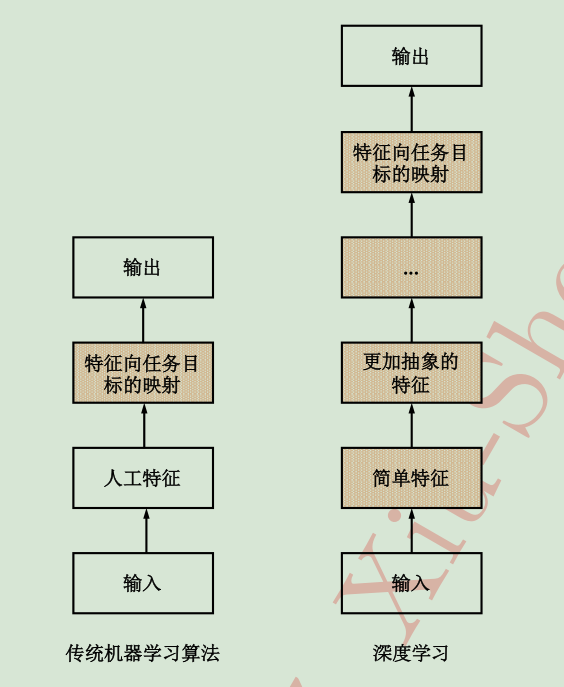
深度学习除了模型学习,还有特征学习、特征抽象等任务模块的参与,借助多层任务模块完成最终学习任务,故称其为“深度”学习。
1.2 深度学习的三盛两落
深度学习的思维范式实际上是人工神经网络(artificial neural networks),从古溯今,该类算法的发展经历了三次高潮和两次衰落。
第一次高潮是二十世纪四十至六十年代当时广为人知的控制论,当时的控制论是受神经科学启发的一类简单的线性模型,其研究内容是给定一组输入信号 $x_1, x_2, x_3, … , x_n$ 去拟合输出信号 $y$ 但是,这样的线性模型,效果极其有限,无法处理 “亦或” 问题。所以被 Marvin Minsky 批判,并提出了两个关键问题:
1、首先,单层神经网络无法处理“异或”问题;
2、其次,当时的计算机缺乏足够的计算能力满足大型神经网络长时间的运行需求。
随后,其研究在60年代末带入“寒冬”
直到 80 年代,Hinton等人提出了反向传播算法,解决了两层神经网络所需要的复杂计算量问题,同时克服了 Minsky 说过神经网络无法解决异或问题,自此神经网络“重获生机”,迎来了第二次高潮,即二十世纪八十至九十年代的连接主义(connectionism)。
然而,好景不长,当时的神经网络过拟合问题严重,且无法解释的这个特性,让人讽刺,神经网络是 “艺术” 而不是 “科学”。至此,它第二次进行 “谷底”。
随着 2012年 ImageNet 竞赛上强势夺冠, 第三次高潮来了,这也是大家熟悉的 深度学习(deep learning)时代。这个时代的到来,跟有效数据的急剧扩增、高性能计算硬件的实现以及训练方法的大幅完善,这三者离不开关系。
二、卷积神经网络基础知识
2.1 基本结构
总体来说,卷积神经网络是一种层次模型(hierarchical model),其输入是原始数据(raw data),如 RGB 图像、原始音频数据等。卷积神经网络通过卷积(convolution)操作、汇合(pooling)操作和非线性激活函数(non-linear activation function)映射等一系列操作的层层堆叠,将高层语义信息逐层由原
始数据输入层中抽取出来,逐层抽象,这一过程便是“前馈运算”(feed-forward)。其中,不同类型操作在卷积神经网络中一般称作“层”:卷积操作对应“卷积
层”,汇合操作对应“汇合层”等等。
最终,卷积神经网络的最后一层将其目标任务(分类、回归等)形式化为目标函数(objective function)。通过计算预测值与真实值之间的误差或损失(loss),凭借反向传播算法(back-propagation algorithm)将误差或损失由最后一层逐层向前反馈(back-forward),更新每层参数,并在更新参数后再次前馈,如此往复,直到模型收敛,从而达到模型训练的目的。