理解 BigTable
BigTable 其实就是 Google 设计的分布式结构化数据表.
Bigtable 的设计动机:
需要存储的数据种类繁多,包括URL、网页内容、用户的个性化设置在内的数据都是Google需要经常处理的
需要存储的数据种类繁多海量的服务请求,Google运行着目前世界上最繁忙的系统,它每时每刻处理的客户服务请求数量是普通的系统根本无法承受的.
商用数据库无法满足需求,一方面现有商用数据库的设计着眼点在于其通用性。另一方面对于底层系统的完全掌控会给后期的系统维护、升级带来极大的便利
为了解决上述的问题, Google 才提出了 BigTable 的概念.
Bigtable 应达到的基本目标
广泛的适用性, Bigtable是为了满足一系列 Google 产品而并非特定产品的存储要求。
很强的可扩展性, 根据需要随时可以加入或撤销服务器.
高可用性, 确保几乎所有的情况下系统都可用.
简单性, 底层系统的简单性既可以减少系统出错的概率,也为上层应用的开发带来便利
Bigtable 数据的存储格式
Bigtable is a sparse, distributed, persistent multidimensional sorted map.
Bigtable 是一个分布式, 多维, 映射表. 表中的数据通过一个行关键字(Row Key)、一个列关键字(Column Key)以及一个时间戳(Time Stamp)进行索引. 在Bigtable中一共有三级索引. 行关键字为第一级索引,列关键字为第二级索引,时间戳为第三级索引。
Bigtable的存储逻辑可以表示为:
(row:string, column:string, time:int64)→string
row 的特点
- Bigtable 的行关键字可以是任意的字符串,但是大小不能够超过 64KB
- 表中数据都是根据行关键字进行排序的,排序使用的是词典序
- 同一地址域的网页会被存储在表中的连续位置
- 倒排便于数据压缩,可以大幅提高压缩率
需要特别注意的是对于一个网站 www.cnn.com 存储在 Bigtable 中的格式是 com.cnn.www
这样倒排的好处是,对于同一域名下的内容,我们可以进行更加快速的索引.
column 的特点
- 将其组织成列族(Column Family)
- 族名必须有意义,限定词则可以任意选定, 比如 “contents”, “title” 等等.
- 组织的数据结构清晰明了,含义也很清楚
- 族同时也是 Bigtable 中访问控制(Access Control)的基本单元
我们从 Bigtable 中读取数据先找到哪一行 然后再去选择读取那个一个 column.
time 的特点
- Google的很多服务比如网页检索和用户的个性化设置等都需要保存不同时间的数据,这些不同的数据版本必须通过时间戳来区分。
- Bigtable中的时间戳是64位整型数,具体的赋值方式可以用户自行定义
选定了 row 和 column 之后,我们就会选择读取哪一个版本的,不同的时间戳代表着不同的数据版本.
典型的 bigtable 存储结构
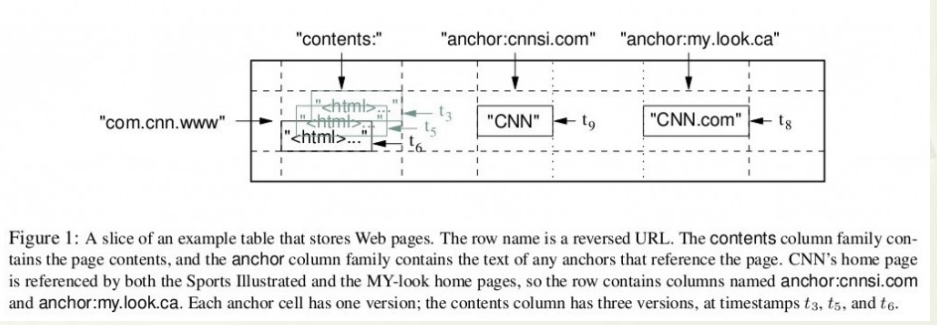
上图是 Bigtable 论文里给出的例子,Webtable 表存储了大量的网页和相关信息。
在 Webtable 中每一行存储一个网页,其反转的 url 作为行键,比如 maps.google.com/index.html 的数据存储在键为com.google.maps/index.html 的行里,反转的原因是为了让同一个域名下的子域名网页能聚集在一起。
上图中的列族 “anchor” 保存了该网页的引用站点(比如引用了CNN主页的站点),qualifier 是引用站点的名称,而数据是链接文本;
列族”contents”保存的是网页的内容,这个列族只有一个空列”contents:”。
“contents”列下保存了网页的三个版本,我们可以用 (“com.cnn.www”, “contents:”, t5) 来找到CNN主页在t5时刻的内容。
以下一个比较典型的 bigtable 存储结构,有点 json 格式的感觉.
1 | table{ |
Bigtable 基本架构
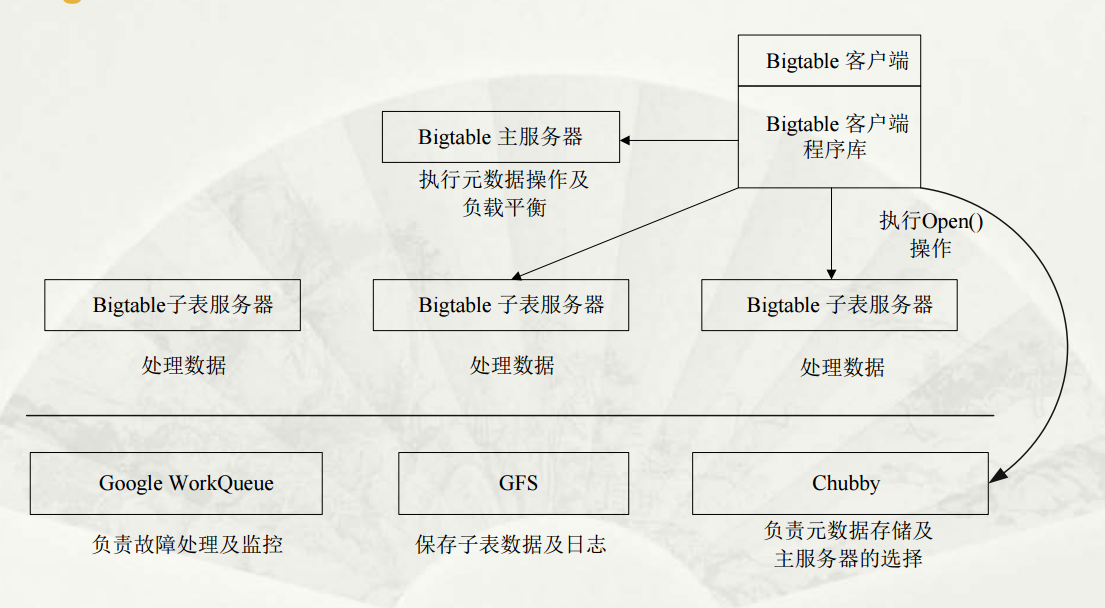
整个 Bigtable 的工作流程,我们会放到后面再介绍,现在先让我们看一下这个基本架构,然后了解 Chubby 的作用.
选取并保证同一时间内只有一个主服务器( Master Server )
获取子表的位置信息。
保存 Bigtable的模式信息及访问控制列表。
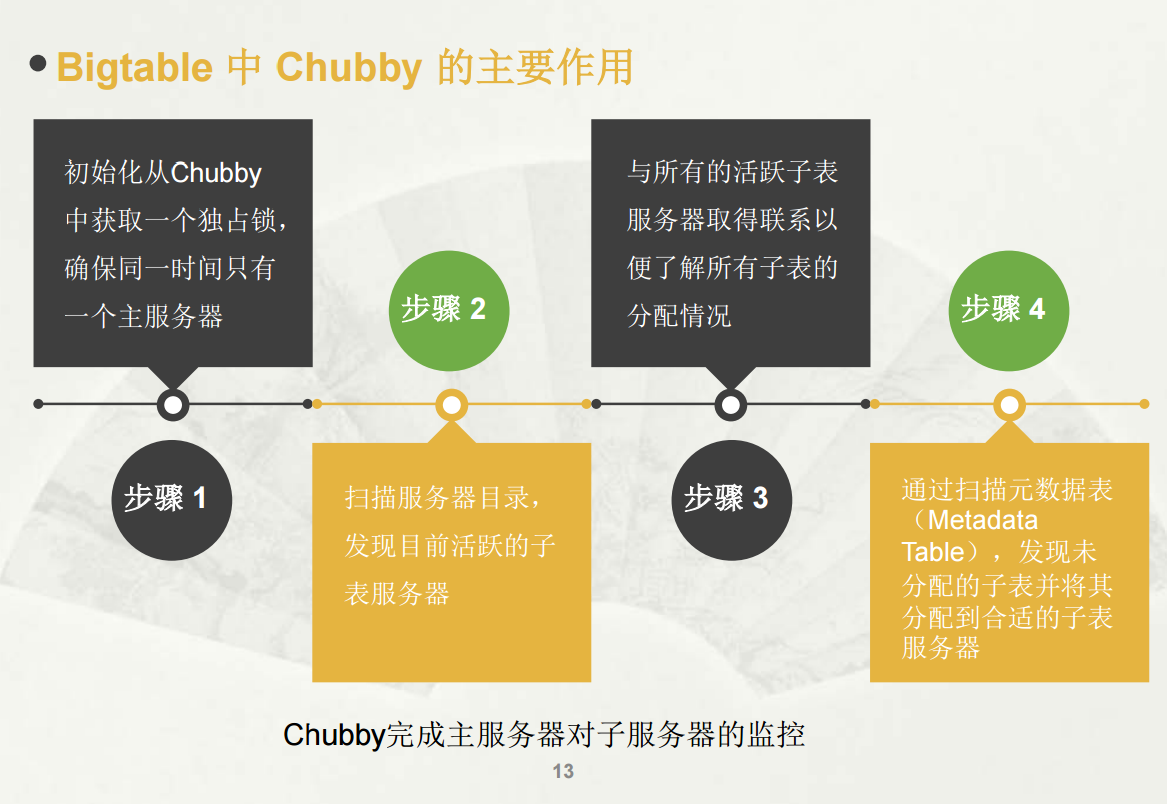
主服务器有什么作用呢?
新子表分配, 当一个新的子表产生时,主服务器通过一个加载命令将其分配给一个空间足够的子表服务器。同时,创建新表、表合并以及较大子表的分裂都会产生一个或多个新子表。
子表服务器状态监控, 主服务器必须对子表服务器的状态进行监控,以便及时检测到服务器的加入或撤销
子服务器之间的负载均衡, 分割由子服务器发起,完成之后子服务器需要向主服务发出一个通知。
这里可能点绕,为了避免”晕车”, 我们再次梳理一下关系.
我们有 Chubby, 主服务器, 子服务器, 子表.
Chubby 负责元数据的存储和选择主服务器.
主服务器复杂子服务器的负载均衡
子服务器负责子表的管理,一个子服务器可以有很多很多张子表,处理对其子表的读写请求,以及子表的分裂或合并。
每个子表的大小在100-200MB范围,一旦超出范围就将分裂成更小的子表,或者合并成更大的子表,
同时,子服务器可以根据负载随时添加和删除。这里子服务器并不真实存储数据,而相当于一个连接 Bigtable 和 GFS 的代理,客户端的一些数据操作都通过子服务器代理间接访问 GFS。
子服务器如何切割子表?

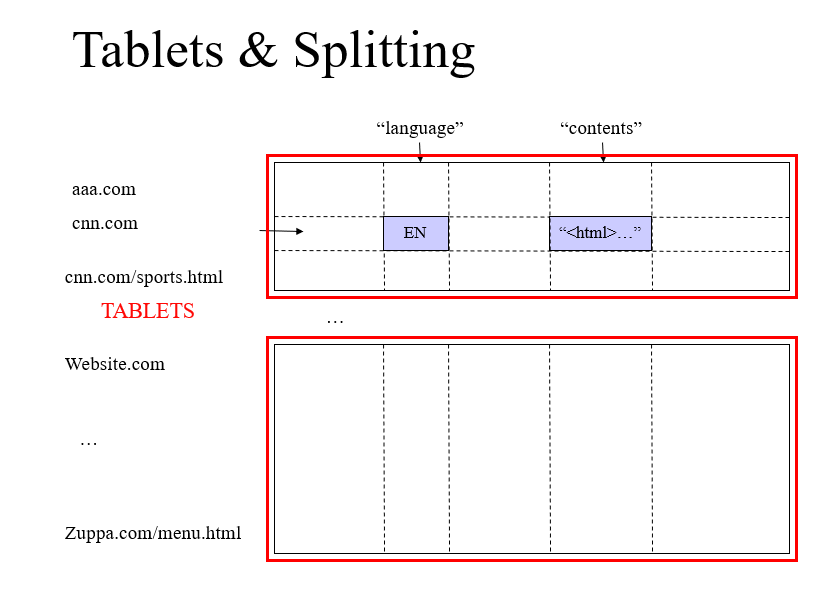
SSTable 格式的基本示意
SSTable 是Google为Bigtable设计的内部数据存储格式。所有的SSTable文件都存储在GFS上,用户可以通过键来查询相应的值。
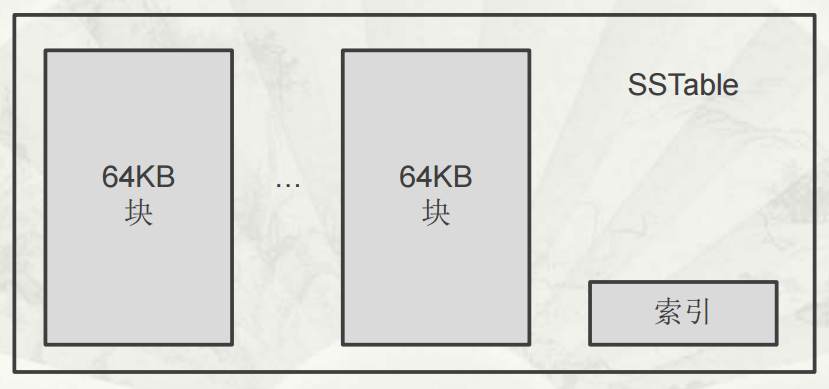
子表实际组成
不同子表的SSTable可以共享
每个子表服务器上仅保存一个日志文件
Bigtable规定将日志的内容按照键值进行排序
每个子表服务器上保存的子表数量可以从几十到上千不等,通常情况下是100个左右
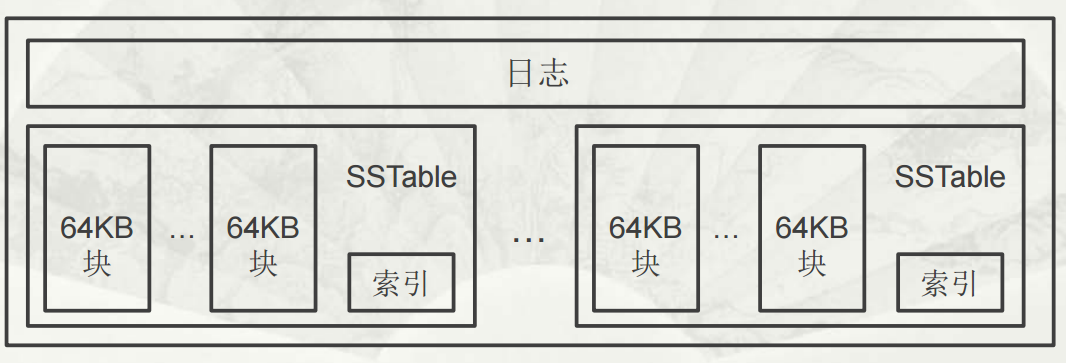
子表地址组成
Bigtable系统的内部采用的是一种类似B+树的三层查询体系
首先是第一层,Chubby file。这一层是一个Chubby文件,它保存着root tablet的位置。这个Chubby文件属于Chubby服务的一部分,一旦Chubby不可用,就意味着丢失了root tablet的位置,整个Bigtable也就不可用了。
第二层是root tablet。root tablet其实是元数据表(METADATA table)的第一个分片,它保存着元数据表其它子表的位置。root tablet很特别,为了保证树的深度不变,root tablet从不分裂。
第三层是其它的元数据子表,它们和root tablet一起组成完整的元数据表。每个元数据片都包含了许多用户子表的位置信息。
可以看出整个定位系统其实只是两部分,一个Chubby文件,一个元数据表。注意元数据表虽然特殊,但也仍然服从前文的数据模型,每个子表也都是由专门的子服务器负责,这就是不需要主服务器提供位置信息的原因。客户端会缓存子表的位置信息,如果在缓存里找不到一个子表的位置信息,就需要查找这个三层结构了,包括访问一次Chubby服务,访问两次子服务器。
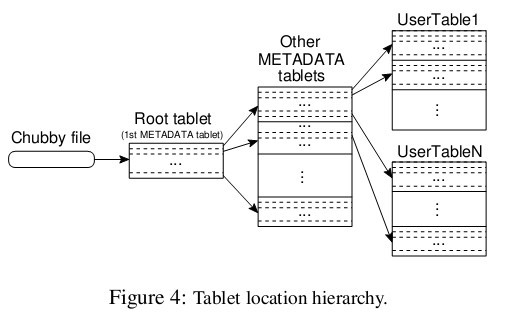
Bigtable 数据存储及读/写操作
子表的数据最终还是写到GFS里的,子表在GFS里的物理形态就是若干个SSTable文件。下图展示了读写操作基本情况。
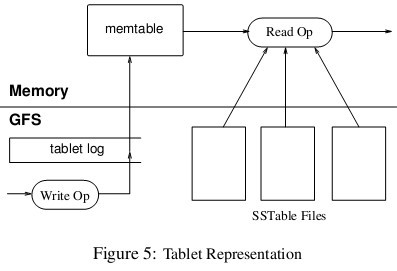
当子服务器收到一个写请求,子服务器首先检查请求是否合法。如果合法,先将写请求提交到日志去,然后将数据写入内存中的 memtable。memtable相当于SSTable的缓存,当memtable成长到一定规模会被冻结,Bigtable随之创建一个新的memtable,并且将冻结的memtable转换为SSTable格式写入GFS,这个操作称为minor compaction。
BigTable和GFS的关系
集群包括主服务器和子服务器,主服务器负责将片分配给子服务器,而具体的数据服务则全权由子服务器负责。
但是不要误以为子服务器真的存储了数据(除了内存中memtable的数据),数据的真实位置只有GFS才知道,主服务器将子表分配给子服务器的意思应该是,子服务器获取了子表的所有SSTable文件名,子服务器通过一些索引机制可以知道所需要的数据在哪个SSTable文件,然后从GFS中读取SSTable文件的数据,这个SSTable文件可能分布在好几台chunkserver上。